Blogginnlegg -
Hackfest og spåkuler - veien mot prediktivt vedlikehold
Rett før sommeren ble Sporveiens første hackfest gjennomført sammen med Microsoft. Du vet kanskje ikke hva en hackfest er? Det er en intens sprintsesjon der man samler folk med ulik kompetanse og i løpet av en kort periode (i vårt tilfelle én uke) jobber med å løse ett eller flere problemer. Les videre for å finne ut hva vi gjorde, hva vi lærte og hva det kan ha å si for at vi skal følge vår strategi og være den beste nordiske løsningen på effektiv og miljøvennlig persontransport i 2020.
Spå i fremtiden?
Det vi ønsket å finne ut av denne uken var om vi kunne forutse feil på sporveksler basert på strømtrekket til drivmaskinene. Dette var mye inspirert av den fantastiske jobben som allerede har blitt gjort i Bane NOR på feltet - og nå ønsket vi i Sporveien å se om vi kunne gjøre det samme på vårt utstyr.

En sporveksel - for dem som ikke kjenner til disse - er en innretning som ligger i sporet for å endre retningen en T-banevogn kan kjøre. Vekslingen mellom posisjoner gjøres ved hjelp av en maskin som flytter skinnene (tungene) fram og tilbake. Disse innretningene er veldig driftssikre, men det kan som med alt annet oppstå problemer eller feil fra tid til annen, og disse må selvsagt utbedres.
Vårt mål denne uken var å finne ut av om vi kunne forutse en feil ved å se på om strømforbruket til drivmaskinene endret seg over tid.
Enorme datamengder
For å måle strømtrekket til drivmaskinene ble det for ett år siden installert sensorer (IoT-sensorer, for den som er ekstra interessert i slikt) som overvåket strømtrekket på 5 slike drivmaskiner i daglig drift. Disse dataene ble så sendt til en server hos leverandøren, som vi så kunne hente dataen fra.
Drivmaskinene har rundt 200 omlegginger i døgnet - og for hver omlegging, som tar drøyt fire sekunder, ble det registrert strømtrekk hvert millisekund. Dette gir i overkant av 4000 datapunkter for hver omlegging. Det er også forskjell på strømtrekket, avhengig av om maskinen legger om fra høyre eller venstre - hvilket ga oss enda mer data å lete i.
Grundige forberedelser
For å være mest mulig effektive og få mest mulig ut av en slik sesjon er forberedelser essensielt. Vi hadde derfor i en god stund jobbet sammen om å laste ned og manipulere all data om omleggingene slik at dataene lå i et format som kunne brukes inn i analysen.
Vi hadde også lastet ned meteorologisk data fra en værstasjon rett ved siden av for å kunne supplere med ved behov (temperatur, nedbør, etc.).
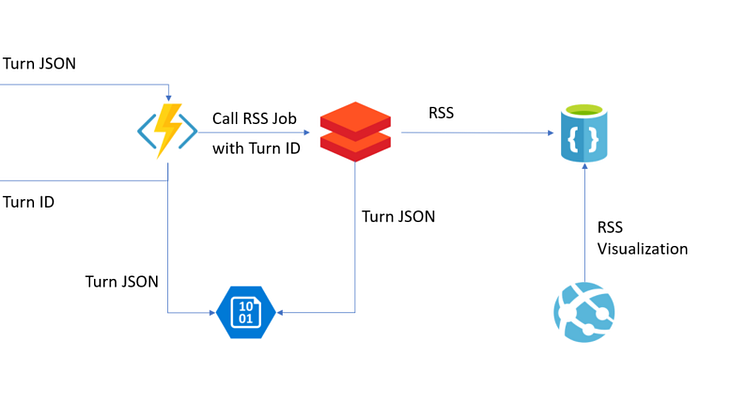
Når det gjaldt teknologi valgte vi for testingens skyld å bruke Azure som skyplattform. Teknologiene som ble valgt for operasjonen var Azure IoT Hub for å motta sanntidsdata, Azure Blob storage for å lagre den ustrukturerte dataen, Databricks for analysearbeidet, Cosmos DB for lagring av preparerte resultater samt PowerBI for å se på resultater. I tillegg hadde vi brukt mye Python for å hente og manipulere all historisk data om omleggingene. Oppsettet er skissert i figuren under.

Vi hadde selvfølgelig også brukt mye tid på å forstå hvordan en sporveksel fungerte, hva normale utfordringer er, samt hvordan man gjør vedlikehold på vekslene. Dette var et samarbeid mellom ressurser fra flere forskjellige fagområder i Sporveien: Infrastrukturavdelingen, analyseavdelingen og digitaliseringsavdelingen var alle representert. For å gi oss mer kunnskap om hvordan endelig oppsett for en slik løsning kunne være hadde vi også blitt enige om å bygge opp et helhetlig system som skulle kjøre prosessen helt fra en omlegging skjedde til resultatet var analysert. Se bilde: Deltakere på Sporveiens Hackfest.
Hva gjorde vi?
I hovedsak ble arbeidet denne uken delt inn i tre faser:
 Fase 1 -
Fase 1 -
Først måtte vi sette opp et teknisk miljø i Azure-plattformen, bygge IoT-mottakspunktet samt prosessen som transformerte den strømmede inndataen.
Fase 2 -
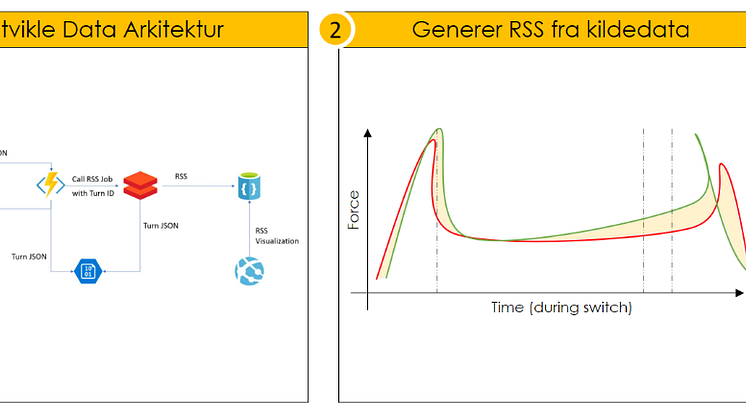
Så bygget vi en prosess som sjekket forskjellen mellom referansekurven (som sier noe om hvordan en optimal omlegging ser ut) og den faktiske kurven fra omleggingen. Da det er snakk om en stor mengde datapunkter beregnet vi kvadratisk gjennomsnitt (RSS) for å beregne én verdi for hver omlegging - som så kunne sammenlignes.
Fase 3 -
Basert på RSS-verdien samt gjennom sammenligning av kurver over tid analyserte vi endringene på oppførselen for å prøve å finne data som kunne tilsi at noe ville feile.
Det sies at 90% av tiden i slike øvelser brukes på dataprepping - og etter denne uken kan vi bekrefte dette. Det å massere dataen tok tid, men også beregningen av alle verdiene krevde mye regnekraft når vi hadde med såpass store datamengder å gjøre - på tross av at både vi og Microsoft hadde brukt mye tid på dataen før vi startet.
Vi jobbet parallelt med fase 1 og 2 helt fra mandag morgen og fram til litt før lunsjtider torsdag. Da var vi endelig der at vi kunne begynne å se på resultatene i sin helhet.
Selv om vi nå hadde gode preparerte analyseresultater var fortsatt datamengden stor siden tidshorisonten for innsamling var så lang. Vi brukte her to metoder for å lete etter feil i dataen: vi lette i tidspunkter der vi visste det hadde oppstått feil, og vi forsøkte i tillegg å se på helheten.
Det var også på dette tidspunktet vi fant ut at vi hadde store hull og avbrudd i sensordataen: for noen av sensorene manglet vi data både i perioder på dagen og også over lengre perioder. Dette gjorde det veldig vanskelig å se etter trender da vi hadde såpass lange brudd i tidsseriene, og tidspunktene vi manglet data for var veldig signifikante.
Men så mot slutten av dagen på torsdagen fant vi gullet vi var ute etter:

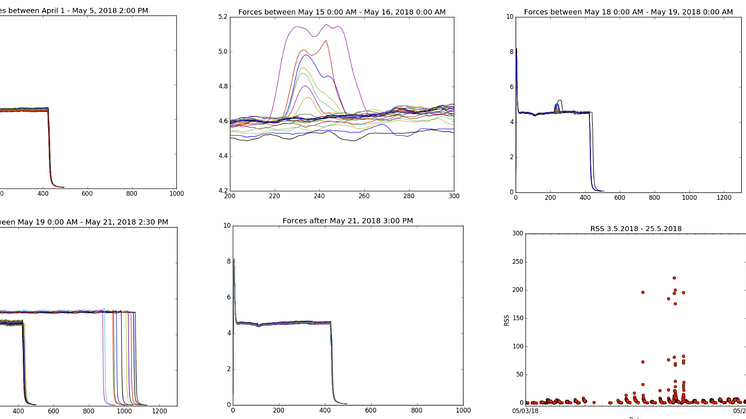
Den 20. mai var det en feil i en sporveksel som medførte stopp av operasjonen og en akutt utbedring av vekselen. På det første bildet over fremkommer det at man hadde normal operasjon i april, mens man på bilde 2 og 3 ser at noe begynte å skje (i perioden 15-19. mai). På bilde 4 ser man at dette forverret seg og at man også fikk omlegginger som ikke låste seg - dette medførte at man måtte smøre vekselen for å løse problemet. På bilde 5 ser man hvordan operasjonen gikk tilbake til normalen etter utbedringen.
Det viktigste bildet er det siste. Det viser endringen i RSS-verdi for mai. I starten av måneden lå denne på det samme nivået, men 14. mai ser man at den begynte å gå oppover - helt til sporvekselen stoppet den 20. mai. Etter 20. mai falt denne og omleggingene var igjen nede på normalt nivå.
Hva lærte vi?
Først og fremst klarte vi å bevise at det med god instrumentering er mulig å fremskaffe måledata som kan hentes ut og analyseres i sanntid for å følge med på helsetilstanden på en sporveksel. Ved å analysere denne tilstanden er det mulig å oppdage feil før det medfører stopp.
Feilen som ledet til stoppen 20. mai ble oppfanget av verktøyet vårt seks dager før den inntraff.
Ved bruk av dette som beslutningsstøtte kunne utbedringen vært gjort i god tid før feilen resulterte i en stopp.
Vi lærte ellers utrolig mye i løpet av denne uken, ikke bare om teknologi og muligheter, men også om vår egen operasjon og hvordan vi håndterer vår egen data. Vi har ekstreme mengder med spennende målinger og sensordata som genereres ute i våre systemer. Her trenger vi gode metoder for å hente inn, lagre, preparere og analysere dataen.
Ved å ha et slikt verktøy integrert i våre arbeidsrutiner vil vi kunne lokalisere - og utbedre - feil før de oppstår. Vi har nå tatt de første stegene på denne veien, og foran oss ligger en lang og spennende reise!
Hva gjør vi videre?
Vi hadde som nevnt en del utfordringer med manglende data på det vi samlet inn. Dette er vi nå i gang med å få løst slik at vi kan ha et mer komplett sett med data og dermed enklere se på endringer over tid.
Vi har også fortsatt arbeidet med å analysere dataen med verktøyene og metodene vi bygget, og har allerede identifisert andre funn som vi jobber videre med. Tanken er at vi skal klare å identifisere terskelverdier for når denne typen feil oppstår, og dermed bruke disse terskelverdiene for å lage alarmer.
Det er også behov for å se på om det er andre sammenfallende data som kan kobles sammen for å forbedre tilstandsovervåkningen ytterligere. Og det gjenstår fortsatt å se dette opp mot værdataen vi samlet inn.
Vår visjon er å integrere dette som et beslutningsstøtteverktøy i våre arbeidsordreprosesser for å gjøre Sporveiens vedlikeholdsarbeid enda bedre.
Dette vil kunne bidra til at vi frakter flere fornøyde passasjerer dit de skal når de skal og til at vi fyller vårt samfunnsoppdrag Mer kollektivtransport for pengene.