Pressemitteilung —
Text aus PDF extrahieren: 5 bewährte Methoden für 2025
Die Textextraktion aus PDF-Dateien gehört zu den häufigsten Aufgaben im beruflichen und akademischen Bereich. Ob aus gescannten Finanzberichten, Dokumentationen oder zur Weiterverwendung von Inhalten – die richtigen Methoden und Tools sind entscheidend für den Erfolg.
In diesem Leitfaden stellen wir Ihnen fünf bewährte Methoden vor: von Online-Diensten über Programmierlösungen bis hin zu OCR-Technologie und KI-gestützten Verfahren. Unabhängig davon, ob Sie Text aus regulären PDFs oder aus Bilddateien benötigen – hier finden Sie die passende Lösung.
Herausforderungen beim Extrahieren von Text aus PDFs {#herausforderungen}
Bevor wir uns mit den Lösungen befassen, ist es wichtig, die typischen Probleme bei der PDF-Textextraktion zu verstehen:
Gescannte PDFs: Diese bestehen aus Bildern und benötigen OCR (Optische Zeichenerkennung) zur Textkonvertierung.
Komplexe Layouts: Tabellen, mehrspaltige Layouts und ungewöhnliche Formatierungen erschweren die Extraktion erheblich.
Geschützte Dokumente: Verschlüsselte oder passwortgeschützte PDFs lassen sich aufgrund gesetzter Beschränkungen oft nicht auslesen.
Schriftarten-Probleme: Eingebettete oder benutzerdefinierte Schriftarten können Extraktionsfehler verursachen.
Methode 1: Online-Tools für kostenlose Textextraktion {#online-tools}
Für schnelle und unkomplizierte Lösungen ohne Softwareinstallation sind Online-Tools ideal geeignet.
PDF Candy
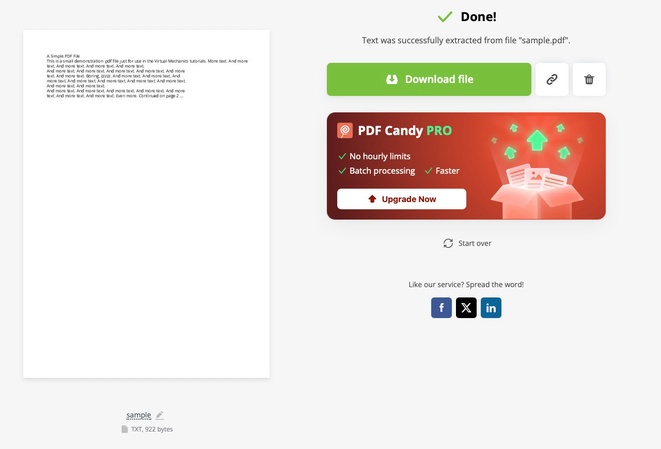
PDF Candy ist ein kostenloser Online-Dienst für die Textextraktion aus PDFs.
Anwendung:
- Rufen Sie PDF Candy auf und laden Sie Ihr Dokument über "Dateien hochladen" hoch
- Klicken Sie auf "Text extrahieren" und anschließend auf "Datei herunterladen"
Vorteile:
- Keine Installation erforderlich
- Unterstützt Batch-Verarbeitung
- Automatische OCR-Funktion
Nachteile:
- 10 MB Dateigrößenlimit für kostenlose Nutzer
PDF2Go
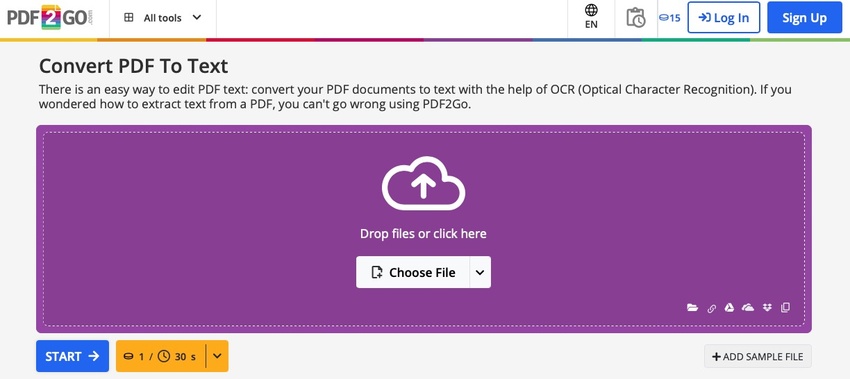
PDF2Go bietet eine benutzerfreundliche Online-Plattform für PDF-zu-Text-Konvertierungen.
Anwendung:
- Öffnen Sie PDF2Go und klicken Sie auf "Datei auswählen"
- Nach dem Upload klicken Sie auf "Start" und dann auf "Herunterladen"
Vorteile:
- Manuelle OCR-Funktionen verfügbar
- Nutzung ohne Registrierung möglich
Nachteile:
- Teilweise unübersichtliche Benutzeroberfläche
Methode 2: Python PyPDF-Bibliothek {#python-pypdf}
Für Entwickler und technikaffine Nutzer bietet Python mit der PyPDF-Bibliothek eine mächtige Lösung zur Automatisierung der Textextraktion.
Code-Beispiel:
# Erforderliche Module importierenfrom pypdf import PdfReader# PDF-Reader-Objekt erstellenreader = PdfReader('beispiel.pdf')# Anzahl der Seiten anzeigenprint(len(reader.pages))# Eine bestimmte Seite auswählenpage = reader.pages[0]# Text aus der Seite extrahierentext = page.extract_text()print(text)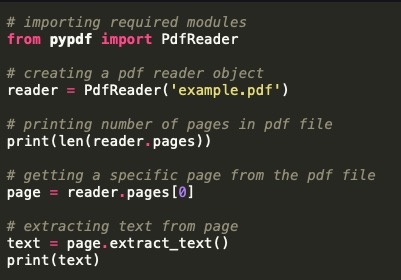
Implementierung:
- Installieren Sie die PyPDF-Bibliothek:
pip install pypdf - Passen Sie den Dateinamen im Code entsprechend an
- Führen Sie das Skript aus
Vorteile:
- Sehr schnelle Verarbeitung großer Dokumente
- Kostenlos und flexibel anpassbar
- Batch-Verarbeitung möglich
Nachteile:
- Erfordert Programmierkenntnisse
- Funktioniert nur bei textbasierten PDFs
Methode 3: OCR für gescannte PDFs {#ocr-methode}
Gescannte PDFs bestehen aus Bilddateien und benötigen spezielle OCR-Technologie zur Texterkennung.
Adobe Acrobat
Adobe Acrobat bietet professionelle OCR-Funktionen für gescannte Dokumente.
Anwendung:
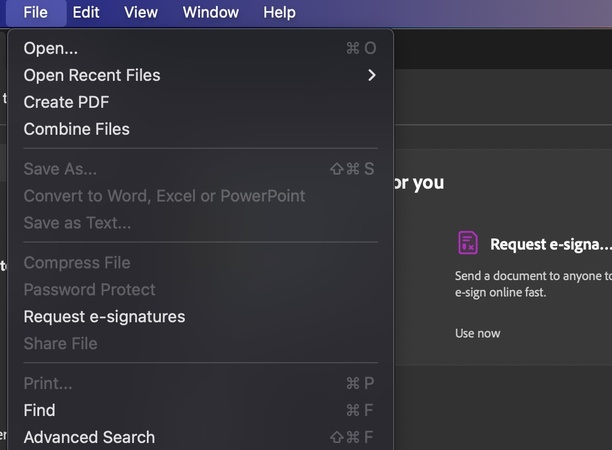
- Öffnen Sie Adobe Acrobat
- Wählen Sie "Datei" → "Öffnen" und laden Sie Ihr PDF
- Acrobat erkennt automatisch gescannte Inhalte und wendet OCR an
Vorteile:
- Hohe Erkennungsgenauigkeit
- Automatische Verarbeitung
- Beibehaltung der Originalformatierung
Nachteile:
- Kostenpflichtige Software
- Hoher Ressourcenverbrauch
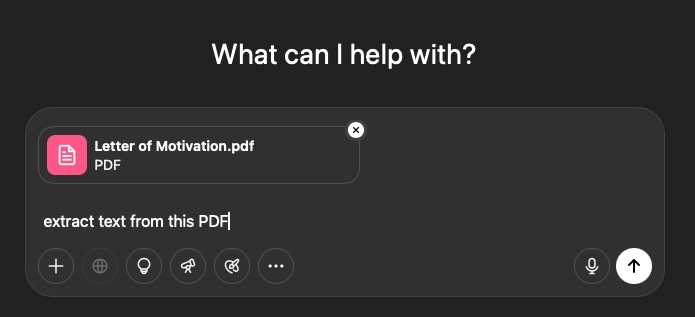
Methode 4: KI-gestützte Extraktion mit ChatGPT {#chatgpt-methode}
Moderne KI-Tools wie ChatGPT können nicht nur Text extrahieren, sondern auch analysieren und zusammenfassen.
Anwendung:
- Öffnen Sie ChatGPT und laden Sie Ihr PDF hoch (Plus-Abonnement erforderlich)
- Geben Sie einen Befehl wie "Extrahiere und fasse den Text aus diesem Dokument zusammen" ein
Vorteile:
- Intelligente Inhaltsanalyse
- Zusammenfassung und Strukturierung möglich
- Mehrsprachige Unterstützung
Nachteile:
- Formatierungen gehen verloren
- Begrenzte Dateigröße
- Kostenpflichtig für erweiterte Funktionen
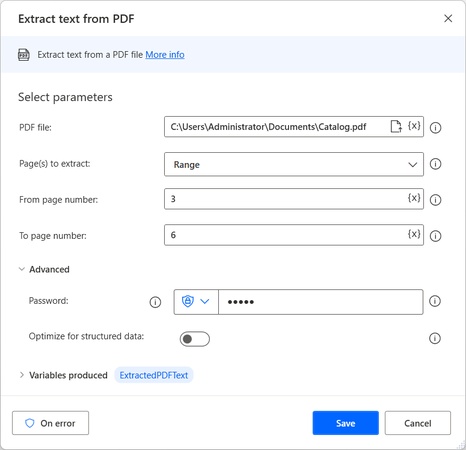
Methode 5: Automatisierung mit Power Automate {#power-automate}
Microsoft Power Automate ermöglicht die Automatisierung wiederkehrender Textextraktions-Aufgaben.
Setup:
- Erstellen Sie einen neuen Flow in Power Automate
- Fügen Sie die Aktion "Text aus PDF extrahieren" hinzu
- Konfigurieren Sie Eingabedatei und Seitenbereich
- Speichern und testen Sie den Workflow
Vorteile:
- Vollständige Automatisierung
- Integration mit Microsoft 365
- Skalierbar für große Dokumentenmengen
Nachteile:
- Komplexe Ersteinrichtung
- Erfordert Microsoft-Abonnement
Bonus-Tipp: Beschädigte PDF-Dateien reparieren
Manchmal scheitert die Textextraktion, weil die PDF-Datei beschädigt oder korrumpiert ist. In solchen Fällen ist eine Reparatur der Datei erforderlich, bevor Text extrahiert werden kann.
Die 4DDiG File Repair Software bietet eine professionelle Lösung für beschädigte PDF- und Textdateien. Das Tool arbeitet vollautomatisch über eine intuitive Benutzeroberfläche und unterstützt verschiedene Dateiformate wie PDF, DOCX, XLS, PPT und mehr.
Schritte zur Reparatur mit 4DDiG File Repair
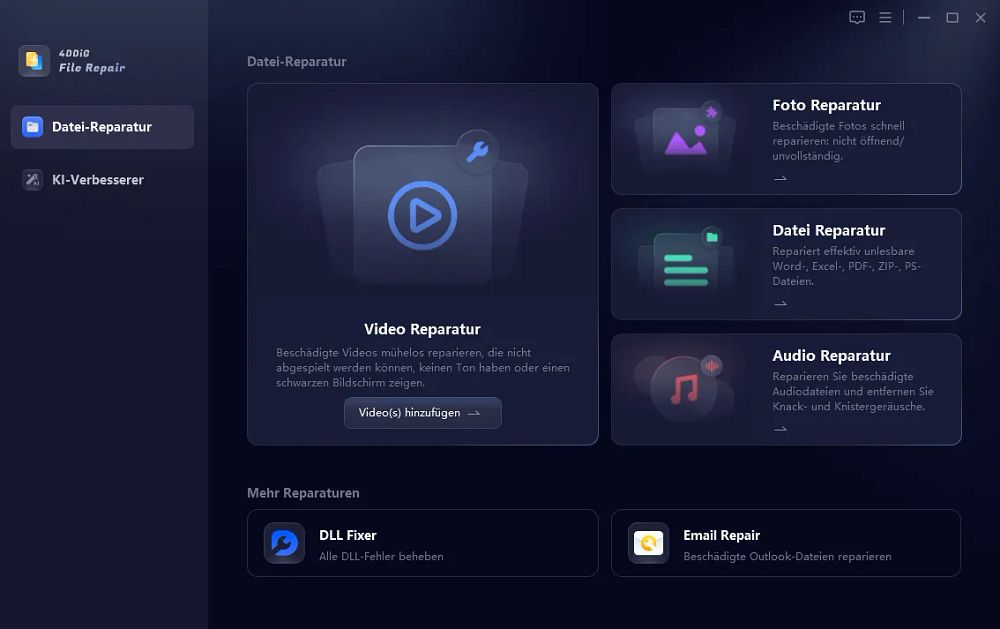
Schritt 1: Software starten und Dateityp wählen
Öffnen Sie 4DDiG File Repair und wählen Sie die Option "Dateien reparieren". Klicken Sie dann auf "Dateireparatur".
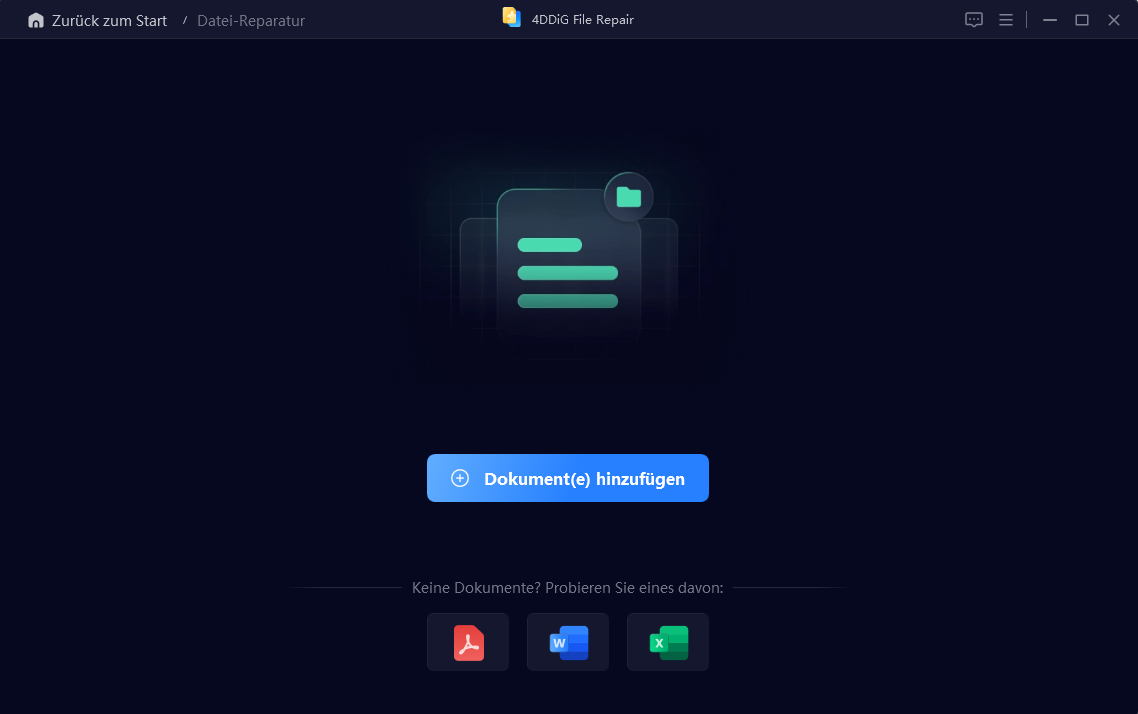
Schritt 2: Beschädigte Dateien hinzufügen
Klicken Sie auf "Dateien hinzufügen" und wählen Sie Ihre beschädigten PDF- oder Textdateien aus.
Schritt 3: Reparatur starten
Klicken Sie auf "Alle reparieren", um den automatischen Reparaturvorgang zu beginnen.
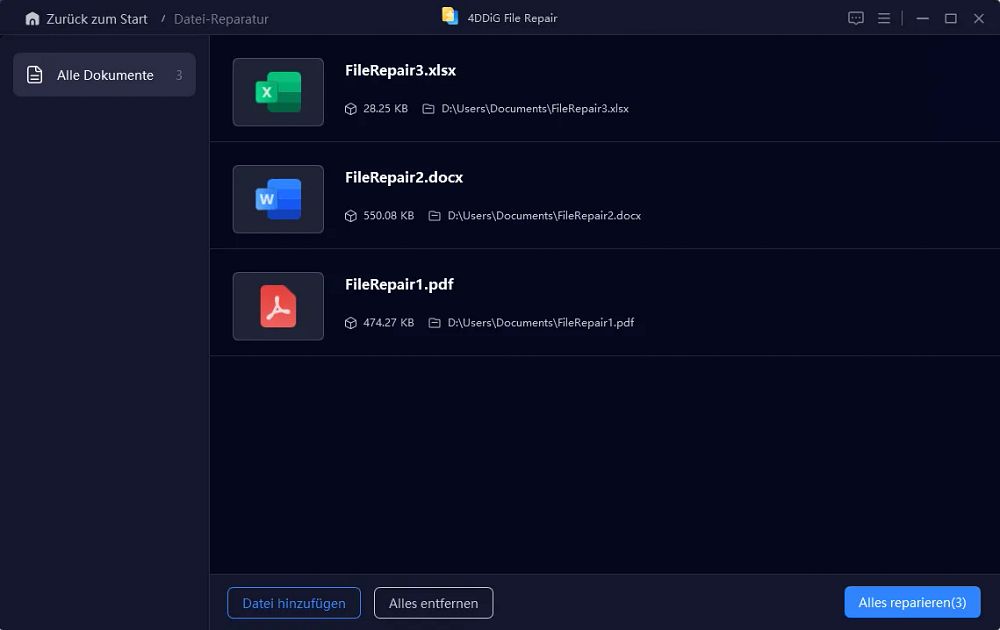
Schritt 4: Ergebnisse überprüfen und speichern
Nach Abschluss können Sie die Ergebnisse in der Vorschau betrachten und die reparierten Dateien speichern.
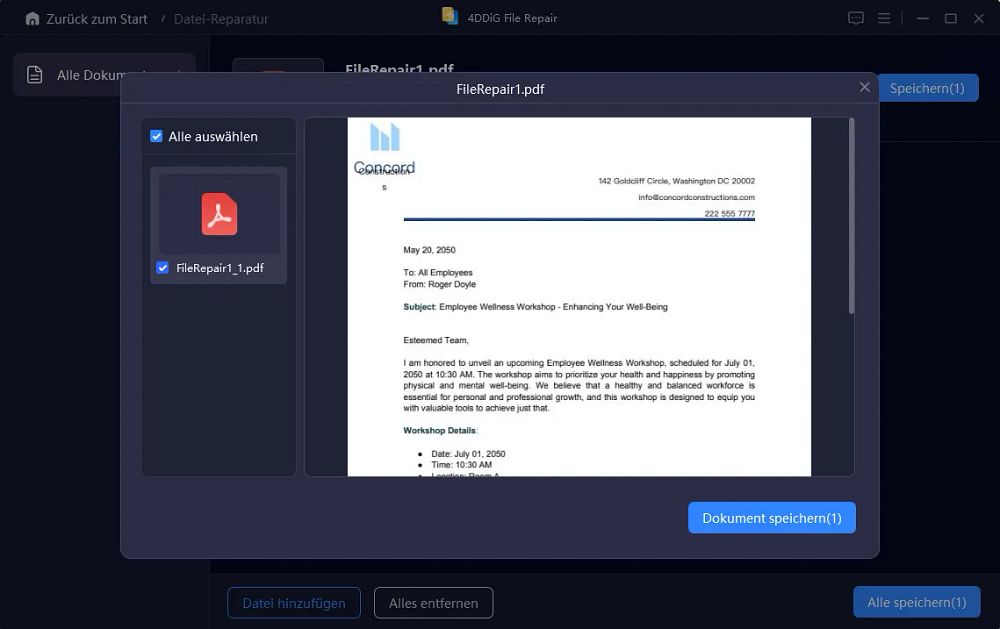
Warum 4DDiG File Repair wählen?
- Benutzerfreundlich: Keine technischen Kenntnisse erforderlich
- Vielseitig: Unterstützt PDF, Word, Excel, PowerPoint und andere Formate
- Effizient: Automatische Erkennung und Reparatur von Dateifehlern
- Sicher: Originaldateien bleiben unverändert
→ 4DDiG File Repair kostenlos herunterladen


Häufig gestellte Fragen {#faq}
Wie extrahiere ich nur bestimmte Seiten aus einem PDF?Die meisten Tools (PDF Candy, Python PyPDF) unterstützen die Auswahl spezifischer Seitenbereiche.
Was tue ich, wenn kopierter Text nur als Symbole erscheint?Dies deutet auf Kodierungsprobleme hin. OCR-Tools können hier helfen, da sie Text visuell erkennen.
Kann man Text aus einer PDF exportieren?Ja, mit allen vorgestellten Methoden können Sie Text extrahieren und in verschiedenen Formaten speichern.
Wie kann ich nur markierten Text aus einer PDF extrahieren?Einige PDF-Reader können Markierungen exportieren. Alternativ verwenden Sie spezialisierte Tools, die Annotations unterstützen.
Kann Adobe Acrobat Text aus einer PDF extrahieren?Ja, Adobe Acrobat bietet sowohl direkte Textextraktion als auch OCR-Funktionen für gescannte Dokumente.
Fazit {#fazit}
Die Textextraktion aus PDF-Dateien lässt sich mit verschiedenen Methoden realisieren – je nach Anforderungen und technischen Kenntnissen:
- Online-Tools für gelegentliche, einfache Aufgaben
- Python-Lösungen für Entwickler mit Automatisierungsbedarf
- OCR-Software für gescannte Dokumente
- KI-Tools für intelligente Analyse und Zusammenfassung
- Workflow-Automatisierung für Unternehmen mit hohem Dokumentenaufkommen
Bei beschädigten oder nicht zugänglichen PDF-Dateien kann die 4DDiG File Repair Software helfen, die Dateien zu reparieren und anschließend erfolgreich Text zu extrahieren.
Wählen Sie die Methode, die am besten zu Ihren spezifischen Anforderungen passt, und nutzen Sie bei Problemen die entsprechenden Reparaturtools für optimale Ergebnisse.

Links
- Wie Sie gescannte PDF-Dateien in höherer Qualität erstellen [Einfach für Einsteiger]
- ChatGPT ein unbekannter Fehler ist aufgetreten beim PDF-Upload? 6 Lösungen!
- Website PDF speichern: Kompletter Leitfaden für alle Geräte (5 Methoden)
- HWP in PDF umwandeln: Die 4 besten Methoden für eine schnelle Konvertierung
Themen
- Technologie, allgemein
Kategorien
- dokument rettung